How to use the newest Oracle JET version in APEX?
While writing this blog post the most recent version of Oracle JET is version 5.1.0. 5.2.0.
5.1 was an interesting version, since charts have been improved to accept an data provider attribute (http://www.oracle.com/webfolder/technetwork/jet/jetCookbook.html?component=chart&demo=dataProvider)
So let’s assume we want to use this version.
Some time ago I published how to integrate JET [2.2.0] into Apex 5.0. It needed quite some setup to do. Some steps probably could have been done in a more elegant way. Additionally see John Snyders recommendations Using Oracle JET from APEX which do eliminate some of the issues that I encountered. For example there is really no need to throw out hammer.js from the theme.
Meanwhile Oracle has made JET available via the Oracle Content Delivery Network (CDN). And this makes it possible to load the necessary JET libraries from this CDN instead of installing it locally to our webserver. Awesome stuff!
I tested this solution with Apex 5.1.1 (on premise) and with Apex 18.1 (on apex.oracle.com).
Which source files are needed?
We need three types of sources.
- require to load and install additional libraries
- the Oracle Jet stylesheets
- various Oracle Jet javascript libraries
Some comments about those files.
Require.js already comes installed in your local Apex installation. It might be a different version, but still is an option to be considered. I only tested using require in the version that matches with Oracle Jet.
Oracle jet now has a file bundled-config.js which adds all of the jet libraries. This might be a bit too much, but it provides a quick and easy way to install JET. In case we only want to use a special visualization, this provides access to way more libraries than needed. I didn’t test if performance improves if I install only the necessary libraries for a special visualization. I hope that because of require, the performance difference would be minimal. Require only loads a file, when it is really needed. Inspecting the network traffic seems to support that notice.
Once those sources are installed to our page, we can copy any example from the Jet Cookbook and use it in our application. Be aware some cookbook examples use additional resources, like JSON data files. You need to copy and reference those too.
New page template
The three source files need to be added to the page. I suggest to create a new page template so that the logic can be reused for multiple pages.
Make a copy of the standard page template. I named it something like “Standard + Jet 5.1”. Then add a few lines to enable Oracle Jet 5.1.0 on this new template.
The two javascript files need to be added to the javascript file section.
https://static.oracle.com/cdn/jet/v5.1.0/3rdparty/require/require.js
https://static.oracle.com/cdn/jet/v5.1.0/default/js/bundles-config.js

As an alternative to the bundles-config.js file, we can install the whole set of the require config in the function declaration section:
//-----------------------------JET STUFF -----------------------------
// alternative source locations
//#APP_IMAGES#oraclejet/main.js
//#IMAGE_PREFIX#libraries/oraclejet/js
requirejs.config({
// Path mappings for the logical module names
paths: {
'knockout': 'https://static.oracle.com/cdn/jet/v5.1.0/3rdparty/knockout/knockout-3.4.2',
'jquery': 'https://static.oracle.com/cdn/jet/v5.1.0/3rdparty/jquery/jquery-3.1.1.min',
'jqueryui-amd': 'https://static.oracle.com/cdn/jet/v5.1.0/3rdparty/jquery/jqueryui-amd-1.12.0.min',
'ojs': 'https://static.oracle.com/cdn/jet/v5.1.0/default/js/min',
'ojL10n': 'https://static.oracle.com/cdn/jet/v5.1.0/default/js/ojL10n',
'ojtranslations': 'https://static.oracle.com/cdn/jet/v5.1.0/default/js/resources',
'text': 'https://static.oracle.com/cdn/jet/v5.1.0/3rdparty/require/text',
'promise': 'https://static.oracle.com/cdn/jet/v5.1.0/3rdparty/es6-promise/es6-promise.min',
'hammerjs': 'https://static.oracle.com/cdn/jet/v5.1.0/3rdparty/hammer/hammer-2.0.8.min',
'signals': 'https://static.oracle.com/cdn/jet/v5.1.0/3rdparty/js-signals/signals.min',
'ojdnd': 'https://static.oracle.com/cdn/jet/v5.1.0/3rdparty/dnd-polyfill/dnd-polyfill-1.0.0.min',
'css': 'https://static.oracle.com/cdn/jet/v5.1.0/3rdparty/require-css/css.min',
'customElements': 'https://static.oracle.com/cdn/jet/v5.1.0/3rdparty/webcomponents/custom-elements.min',
'proj4js': 'https://static.oracle.com/cdn/jet/v5.1.0/3rdparty/proj4js/dist/proj4'
},
// Shim configurations for modules that do not expose AMD
shim: {
'jquery': {
exports: ['jQuery', '$']
}
}
});
If you want to use this option and Jet 5.2 then I suggest to look into the 5.2.0 bundles-config.js file, and copy the correct paths out of it.

Remember above code is not needed! It comes preconfigured in the bundle-config.js file. I offer it only as an alternative installation that gives a little more control over the libraries.
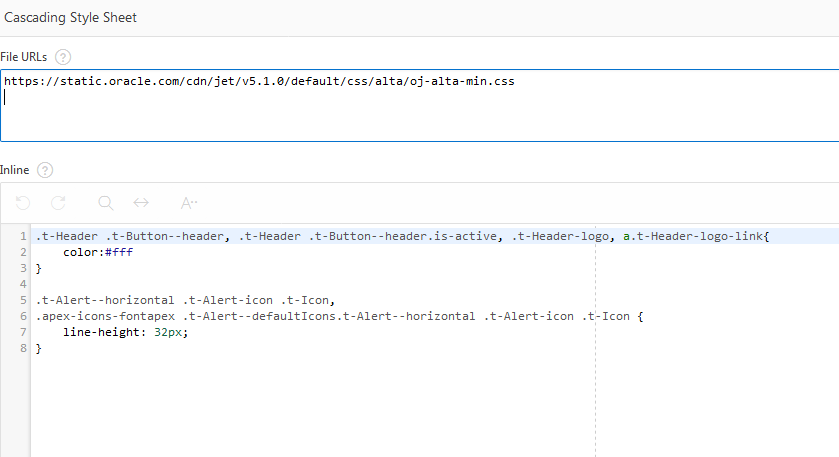
Finally we need to add some css. Add the link for the JET style to the CSS file section.
https://static.oracle.com/cdn/jet/v5.1.0/default/css/alta/oj-alta-min.css
And additionally you might want to add a little inline css. See the issues section for an explanation.
And finally use this new page template for your page.
Example result
And this is how using Oracle Jet 5.1/5.2 in Apex can look like.
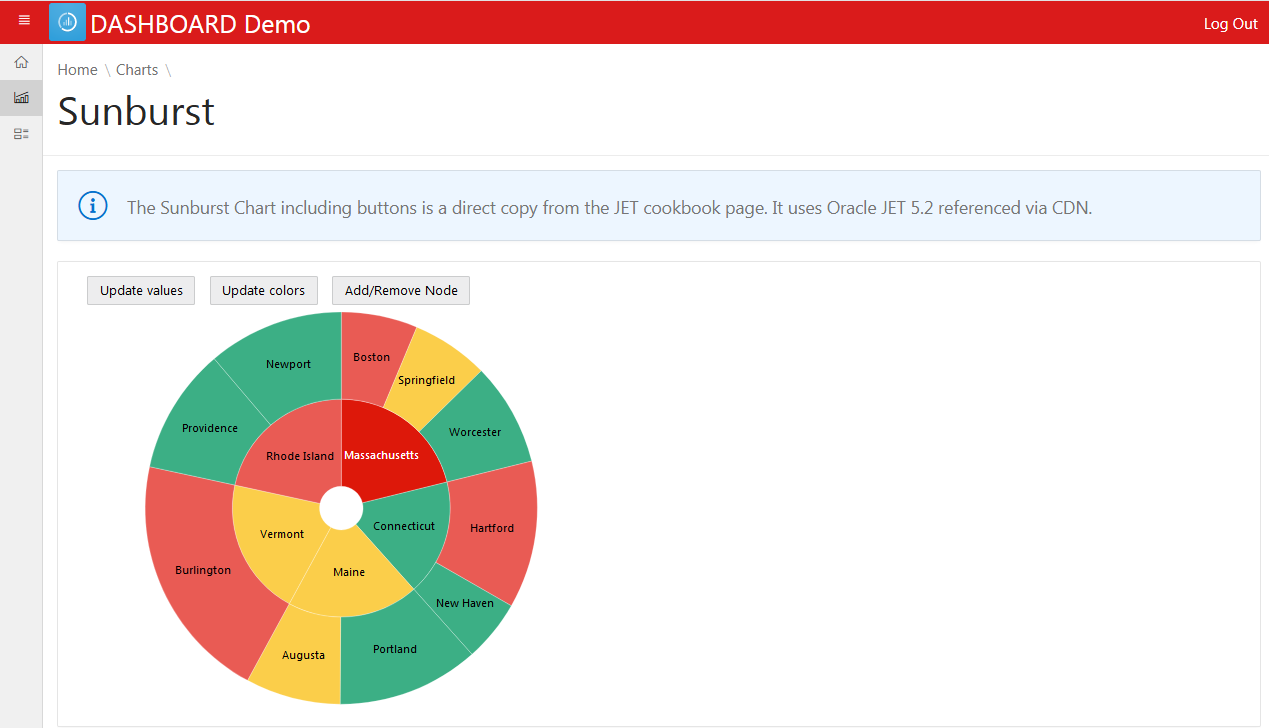
The source code for that chart can be found at the end of the post. Or go to the Jet Cookbook and try it our there. Did you notice, you can spin the whole wheel around?
Issues
There are some minor problems that I encountered. Especially some css issues because JET overwrites several of the Apex Theme css settings. Which is not good. I made a sample demo to show the issues. I only tested it with the red theme style, but I think the issues persist in all styles.
Theme Bug Demo
I do have css based workarounds for the issues I found so far. The solution is also demonstrated in the demo app. Here is the css code that can be added to the page or the template (css section).
.t-Header .t-Button--header, .t-Header .t-Button--header.is-active, .t-Header-logo, a.t-Header-logo-link{
color:#fff
}
.t-Alert--horizontal .t-Alert-icon .t-Icon,
.apex-icons-fontapex .t-Alert--defaultIcons.t-Alert--horizontal .t-Alert-icon .t-Icon {
width: 48px;
height: 48px;
line-height: 48px;
}
I think those issue are really bugs. And the Apex team and the Jet team can both be held responsible. The APEX side should have used a better css specificity for the header styles, the JET side should not set styles for things like a:visited for the whole html page.
And I believe there are more side effects. That is also the main reason why I would add JET only to specific pages. And why I would avoid mixing normal apex charts with newer version JET charts. Don’t mistake me, I made a few simple tests and it worked. I could create a region with a normal apex jet chart (apex 5.1) and combine it with a region using a CDN loaded JET chart (Legend + PictoChart). I just didn’t test it thoroughly enough to recommend it.
What is a CDN and is it safe?
https://en.wikipedia.org/wiki/Content_delivery_network
A content delivery network provides ressources, like in the JET case, javascript and css files, in a way that optimizes access times. So if a user accesses our application from Europe, the ressources will be delivered from a European server. If the user sits in America, an American server is choosen to deliver the files. This also frees up some bandwidth for our own webserver. After the first load, the browser usually caches the files.
If different applications all use the same remote ressource via CDN, the browser can reuse the cached files. This is especially interesting for the very common libraries, like JQuery.
But performance is not the only argument. With Oracle JET I find it way more convinient to load the newest JET version directly from Oracle instead of going through the hassle and install it to the local webserver. Often this involves using deployments scripts and documenting what exactly to do, so that in an enterprise environment, the same steps can be later made for the production server.
But is it safe to use? The most secure method is, if you download the js files from a trusted source (Oracle CDN). Then inspect each file, if there is any malicious code in it. Once you are sure it is safe, you install the files onto your own webserver and serve the ressources from there.
One of the most basic security features is to use HTTPS and not HTTP, especially when accessing remote ressources. This lowers the chance for man in the middle attacks essentially.
Especially the DNS lookup to the CDN server might be a performance drain. But in terms of web speed there are many things to consider.
Pros
- Ease of installation
- Performance boost for global user base
- Browsers limit parallel loads from the same source. Loading additional ressources from a second source circumvents that issue.
- Bandwidth moved from own webserver to CDN
Cons
- Less control over the logic that is loaded – you need to trust the CDN provider
- CDN provider could be down
- For local users CDN will be slower than serving from local webserver
quick conclusion
Oracle JET via Oracle CDN is a good concept especially during a developement and testing phase. For on premise production usage you might want to consider to install Oracle JET to your local webserver and run it from there.
more
Here are a few links that I found interesting and that cover several other topics about using or not using a CDN.
updates and addendum
Oracle JET 5.2.0
Very recently Oracle JET 5.2.0 was released. I test it only very briefly. You just have to change the version number in the source file path.
Here is the official release schedule for the future Jet versions.
Sunburst Example
The following code is a direct copy from the Oracle Jet Cookbook.
Create a static region and add this as the region source.
Unfortunatly I encounter some issues when posting oj-tags here. The code is missing in the final view. Best way is to go directly to the source and copy the code from there. Everything inside the body tag is needed.
<div id="sampleDemo" class="demo-padding demo-container">
<div id="componentDemoContent" style="width:1px;min-width:100%;">
<div id='sunburst-container'>
<div style="padding-left:16px;float:left;">
Update values
</div>
<div style="padding-left:16px;float:left;">
Update colors
</div>
<div style="padding-left:16px;float:left;">
Add/Remove Node
</div>
<br style="clear:left;" />
</div>
</div>
</div>
Or copy the code from this screenshot

Add this on the page level to the “function and global variable declaration”:
require(['ojs/ojcore', 'knockout', 'jquery', 'ojs/ojknockout',
'ojs/ojbutton', 'ojs/ojsunburst'],
function(oj, ko, $)
{
function SunburstModel() {
var self = this;
var colorHandler = new oj.ColorAttributeGroupHandler();
var MA = createNode("Massachusetts", "0", getValue(), getColor());
var CT = createNode("Connecticut", "1", getValue(), getColor());
var ME = createNode("Maine", "2", getValue(), getColor());
var VT = createNode("Vermont", "3", getValue(), getColor());
var RI = createNode("Rhode Island", "4", getValue(), getColor());
addChildNodes(MA, [
createNode("Boston", "00", getValue(), getColor()),
createNode("Springfield", "01", getValue(), getColor()),
createNode("Worcester", "02", getValue(), getColor())
]);
addChildNodes(CT, [
createNode("Hartford", "10", getValue(), getColor()),
createNode("New Haven", "11", getValue(), getColor())
]);
addChildNodes(ME, [
createNode("Portland", "20", getValue(), getColor()),
createNode("Augusta", "21", getValue(), getColor())
]);
addChildNodes(VT, [
createNode("Burlington", "30", getValue(), getColor())
]);
addChildNodes(RI, [
createNode("Providence", "40", getValue(), getColor()),
createNode("Newport", "41", getValue(), getColor())
]);
var nodes = [MA, CT, ME, VT, RI];
function createNode(label, id, value, color) {
return {label: label,
id: id,
value: value,
color: color,
shortDesc: "<b>" + label +
"</b>
Value: " + value};
}
function addChildNodes(parent, childNodes) {
parent.nodes = [];
for (var i = 0; i < childNodes.length; i++) {
parent.nodes.push(childNodes[i]);
}
}
function getValue() {
return Math.round(50 + 100 * Math.random());
}
function getColor() {
return colorHandler.getValue(Math.floor(Math.random() * 4));
}
self.nodeValues = ko.observableArray(nodes);
self.valueButtonClick = function(event) {
for (var i = 0; i < nodes.length; i++) {
if (Math.random() < 0.4)
nodes[i].value = getValue();
for (var j=0; j < nodes[i].nodes.length; j++) {
if (Math.random() < 0.4)
nodes[i].nodes[j].value = getValue();
}
}
self.nodeValues(nodes);
return true;
}
self.colorButtonClick = function(event) {
for (var i = 0; i < nodes.length; i++) {
if (Math.random() < 0.3)
nodes[i].color = getColor();
for (var j=0; j < nodes[i].nodes.length; j++) {
if (Math.random() < 0.3)
nodes[i].nodes[j].color = getColor();
}
}
self.nodeValues(nodes);
return true;
}
self.nodeButtonClick = function(event) {
if (nodes.length <= 5) {
var newNode = {
id: "5", value: getValue(),
color: getColor(), label: "New York",
nodes: [
{id: "50", value: getValue(),
color: getColor(), label: "New York City"},
{id: "51", value: getValue(),
color: getColor(), label: "Albany"}
]
};
nodes.push(newNode);
}
else {
nodes.pop();
}
self.nodeValues(nodes);
return true;
}
}
var sunburstModel = new SunburstModel();
$(
function()
{
ko.applyBindings(sunburstModel,
document.getElementById('sunburst-container'));
}
);
});














































 Fairly easy, once we know what to do. In the future I might use this session storage for other things too.
Fairly easy, once we know what to do. In the future I might use this session storage for other things too.

