To show (not to edit) pretty code inside an APEX application in the past I had used the libraries that were deployed along with APEX, like CodeMirror (see https://svenweller.wordpress.com/2015/12/07/apex-5-syntax-highlighting/) and CkEditor. In APEX 21 CkEditor got a new version and CodeMirror is not supplied anymore since several APEX versions now. But there is a new very lightweight alternative, which is prism.
In my use case I need this to quickly present currently running edition based plsql code.
Implementation
Step 1) Load code into a hidden page item
I use a before region process to load the data (=code) into an item. Assuming item name P1_CODE for further references.
Step 2) Add prism files to the page
Javascript file urls
#PRISMJS_DIRECTORY#prism.js
CSS file urls
#PRISMJS_DIRECTORY#prism.css
Note that the substitution variable PRISMJS_DIRECTORY is automatically provided and resolved to the path “/i/libraries/prismjs/1.24.1/” and is updated in future versions.
Step 3) Show item in html region and choose the language
Add this to the html code section of a static region.
Note that you should set the correct language that you want to show. In my case it is language-plsql.
<pre><code class="language-plsql">&P1_CODE.</code></pre>
The value in the item is automatically html escaped. In case the logic that loads the code into the item did already escape it, you can also choose not to escape it again, by using an escape filter like &P1_CODE!RAW. . Just be aware of potential security issues, if you do not do that correctly.
A list of possible languages can be found here. However not all of those languages are added in the APEX deployment.
Step 4) Customize a few colors
I didn’t like the coloring for plsql or sql code. Especially I prefer to show comments in green. This can be changed with a few lines of css.
Add this to the inline css section of the page
/* prism plsql colorization */
.token.comment {
color: #119b01;
}
.token.string {
color: #0c6cb97c;
}
.token.keyword {
color: #8C009B;
font-weight: bold;
}
Very quick and easy to implement.
If you want different settings, simply inspect the code snippet using the browser. That is one of the advantages of prism. The code is tokenized using span tags and the appropriate classes. We can easily see what kind of token a certain element is and simply change the style for the class we want.
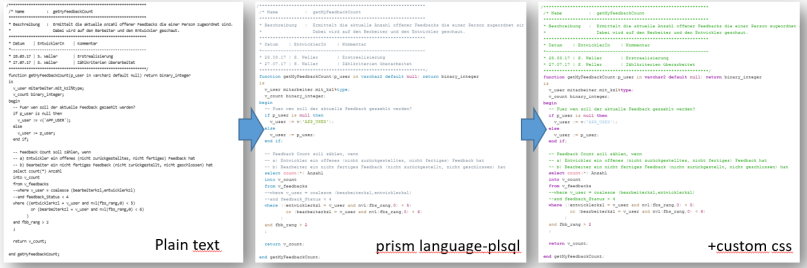
Result
Here is a crude overview how the result looks like

Additional considerations
prism has the possibility to add many additional features. However those features come as plugins that are packed directly into the .css and .js files. To use them, one would have to add/replace the library that is used by APEX. I didn’t investigate in detail, which plugins are already inclued. For example line numbering does NOT seem to work out of the box.
This would do the trick with the line numbers, if the line-numbers plugin is integrated.
<pre class="line-numbers" data-start="50"><code class="language-plsql">&P1_CODE.</code></pre>
Conclusion
For simple requirements prism allows a very easy and quick way to add syntax highlighting to code. For more complex requirements (like editing code) a different library might be better suited. The possibility to have dedicated subtitution strings for several libraries is very welcome.
One additional note. I tried to use the markdown editor item type as an alternative, but the effort to make it work for my simple requirements, was too high. A markdown editor simply serves a different purpose.



