Motivation
In recent times I speculate where and when to use scalable sequences. Especially if it makes sense to use them in general for sequence driven ID columns of larger tables. I know this sounds a bit like an early sign of CTD (compulsive tuning disorder), but at least I’m aware of it.
Scalable sequences offer a performance benefit in certain special situations (hot block, index contention). This post is not about those benefits.
I assume the reader has a basic understanding what a scalable sequence is. If not, check out this older post of mine: All about sequences .
A scalable sequence provides larger numeric values than a normal sequence does.
A normal sequence => 3
A scalable sequence => 10176700000003
Here I only analyze and test the effects of those bigger numbers, especially for indexes.
Side note: The first 3 digits of the scalable sequence are the instance number + 100. The second 3 digits are the session id. The remainder is the normal sequence value. Different sessions provide different numbers and by this the sequence numbers are not monotonously increasing anymore. At least not when looking at multiple sessions. Which also means inserts are done all over the index and not only on the right hand side of the index.
Bigger numbers need more storage
The number 3 needs 2 bytes, the number 10176700000003 needs 8 bytes of storage. Use the DUMP function to measure it. Values provided by scalable sequences might use up to 18 bytes of storage.
This effects multiple areas, table segment size but also indexes tend to be bigger. We can safely assume the sequences are used to provide values for ID columns which are almost always supported by an unique index. But there are also foreign key columns using those numbers and there the index will not be unique for similar ID values.
Because values are bigger less index references fit into a single index block – meaning we need more index blocks. Here I focus explictly on the size of indexes and not on the size of columns. I believe that a few additional bytes for a whole table row is usually not relevant. In case of an index however the whole row is that single value plus references (index branch block) or rowids (index leaf block).
For comparison reasons I also check the size of an reverse key index since they were used in the past to combat index contention issues. Scalable sequences are the new kid in town that should replace reverse key indexes.
So let’s measure it.
Testscript 1 – single session insert
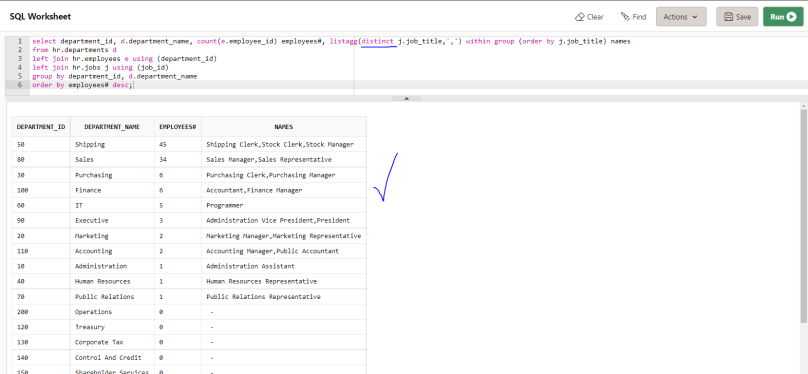
First we create a table with 3 number columns. Then we create a normal and a scalable sequence that provide some values. We add two normal and a reverse key index on those 3 columns and populate the table with values originating from the sequences.
------------------------------------------------------------------------------- Scenario: Test index size -------------------------------------------------------------------------------- -- create a table with two columns files with IDs create table test_sequence_effects (id_normal number, id_scalable number, id_reverse number); -- create a normal and a scalable sequence create sequence test_sequence_normal; create sequence test_sequence_scale scale; -- create 3 indexes create index test_sequence_normal_ix on test_sequence_effects(id_normal); create index test_sequence_scale_ix on test_sequence_effects(id_scalable); create index test_sequence_reverse_ix on test_sequence_effects(id_reverse) reverse ; -- insert 1 million datapoints insert into test_sequence_effects select test_sequence_normal.nextval, test_sequence_scale.nextval, test_sequence_normal.nextval from dual connect by level <= 1000000; commit; -- create statistics execute dbms_stats.gather_index_stats(user, 'TEST_SEQUENCE_NORMAL_IX',estimate_percent => 100); execute dbms_stats.gather_index_stats(user, 'TEST_SEQUENCE_SCALE_IX',estimate_percent => 100); execute dbms_stats.gather_index_stats(user, 'TEST_SEQUENCE_REVERSE_IX',estimate_percent => 100);
result after single session insert
We can have a look at the index statistics and the segment sizes.
-- check index stats
select index_name, blevel, leaf_blocks, distinct_keys, clustering_factor
from dba_indexes
where index_name like 'TEST_SEQUENCE_%';
| INDEX_NAME | BLEVEL | LEAF_BLOCKS | DISTINCT_KEYS | CLUSTERING_FACTOR |
|---|---|---|---|---|
| TEST_SEQUENCE_NORMAL_IX | 2 | 1999 | 1000000 | 4271 |
| TEST_SEQUENCE_SCALE_IX | 2 | 3379 | 1000000 | 4271 |
| TEST_SEQUENCE_REVERSE_IX | 2 | 2965 | 1000000 | 999996 |
Now all three indexes still have the same blevel, meaning for a single direct index access the performance should be identical. However when the number of entries increases eventually the ID values created by a scalable sequence might create a new level in the btree before the same happens for IDs from a normal sequence. I tested when this will happen. If you are curious check out the appendix section “blevel3 break point”, but try to guess the value before you check.
-- check index size
select segment_name, segment_type, segment_subtype, blocks, bytes/1024/1024 as size_in_MB
from user_segments
where segment_name like 'TEST_SEQUENCE_%';
| SEGMENT_NAME | SEGMENT_TYPE | SEGMENT_SUBTYPE | BLOCKS | SIZE_IN_MB |
|---|---|---|---|---|
| TEST_SEQUENCE_EFFECTS | TABLE | ASSM | 4352 | 34 |
| TEST_SEQUENCE_NORMAL_IX | INDEX | ASSM | 2176 | 17 |
| TEST_SEQUENCE_REVERSE_IX | INDEX | ASSM | 3072 | 24 |
| TEST_SEQUENCE_SCALE_IX | INDEX | ASSM | 3584 | 28 |
The scaleable index in this experiment is 65% larger than the normal index. The cause for this increment can be attributed directly to the bigger numbers that needs to be stored.
We have to keep in mind that the test scenario was run in a single session. In reality multiple sessions will be used to run the insert(s). This is where scalable sequences should give a performance boost, even at the cost of potentially slightly higher storage consumption.
Testscript 2 – parallel inserts from multiple sessions
Ok now repeat the same experiment but using multiple sessions instead of a single session.
I created a code block that repeatetly does single row inserts in blocks of 10 and waits 1 second. This was run in up to 100 parallel sessions using dbms_scheduler jobs until approximately 1 million rows were inserted. The code for this test can be found in the appendix section “Testscript 2 – code”. Because of the 1 sec. pause this will run for some time.
Index stats after parallel inserts
| INDEX_NAME | BLEVEL | LEAF_BLOCKS | DISTINCT_KEYS | CLUSTERING_FACTOR |
|---|---|---|---|---|
| TEST_SEQUENCE_NORMAL_IX | 2 | 3649 | 1000198 | 943211 |
| TEST_SEQUENCE_SCALE_IX | 2 | 6577 | 1000198 | 32329 |
| TEST_SEQUENCE_REVERSE_IX | 2 | 3240 | 1000198 | 986633 |
The number of blocks increased for all indexes. But more importantly we see that the clustering factor for the normal index went through the roof and is now close to the number of rows in the table. Which is bad. It also shows that scalable sequences seem to keep the promise of avoiding index contention and hot blocks, even if this test was not set up to measure any performance implications.
If you want to know more about clustering factor, read appendix section “index clustering factor”.
Side note: There were a few more rows inserted than in the single session approach (0.02%). That was because how the stopping mechanism worked for the parallel jobs. It does not influence the comparison at all.
Index sizes after parallel inserts
| SEGMENT_NAME | SEGMENT_TYPE | SEGMENT_SUBTYPE | BLOCKS | SIZE_IN_MB |
|---|---|---|---|---|
| TEST_SEQUENCE_EFFECTS | TABLE | ASSM | 4480 | 35 |
| TEST_SEQUENCE_NORMAL_IX | INDEX | ASSM | 3840 | 30 |
| TEST_SEQUENCE_REVERSE_IX | INDEX | ASSM | 3328 | 26 |
| TEST_SEQUENCE_SCALE_IX | INDEX | ASSM | 6784 | 53 |
So the size of a normal index rose from 17 to 30MB (76% increase) and for the scaleable index from 28 to 53MB (83%). The reason for both increaments in size should be because now we see more 50-50 index block splits resulting in a considerable amount of blocks not being full and rarely being reused.
Overall the size didn’t explode, but it is still a noticable amount.
Side note: It is possible to shrink the indexes after such parallel insert sessions, but the effect is not great. Shrink and coalesce really should be considered when frequent deletes are run against the table. Scalable sequences potentially can provide values that might fill some of the gaps created by deletes. An index rebuild is not needed or advisable as long as more inserts are to come.
Conclusion
Values created by scalable sequences are using more storage space than values from normal sequences. For indexes we can expect a growth in index size between 50% and 100% compared to a normal index. The growth is partially because of larger numbers but also because there will be more not yet used space in many of the index blocks (caused by 50-50 index block splits instead of 90-10).
The clustering factor for scalable sequences always is better or equal than any alternative.
For all customers that I work with such an increment in storage size would not be any problem at all, especially if there is a performance improvement.
For me the storage size increase is not an argument against scalable sequences.
Appendix
Testscript 2 – code
--------------------------------------------------------------------------------
-- Scenario: Test index size after parallel inserts
--------------------------------------------------------------------------------
-- cleanup logic
drop table test_sequence_effects purge;
drop sequence test_sequence_normal;
drop sequence test_sequence_scale;
execute dbms_scheduler.drop_program('test_sequence_do_inserts');
begin
for j in (select job_name from all_scheduler_jobs where job_name like 'TEST_SEQUENCE%') loop
dbms_scheduler.drop_job(j.job_name);
end loop;
end;
/
--------------------------------------------------------------------------------
-- create a table with three columns to be filled with IDs
create table test_sequence_effects
(id_normal number,
id_scalable number,
id_reverse number);
-- create a normal and a scalable sequence
create sequence test_sequence_normal;
create sequence test_sequence_scale scale;
-- create 3 indexes
create index test_sequence_normal_ix on test_sequence_effects(id_normal);
create index test_sequence_scale_ix on test_sequence_effects(id_scalable);
create index test_sequence_reverse_ix on test_sequence_effects(id_reverse) reverse ;
-- insert 1 million datapoints
-- run as 100 parallel scheduled jobs
-- each job inserts a batch of 10 IDs using single row inserts
-- each job waits for 10 seconds before the next batch is run
-- each job stops after the max number for the normal ID is reached.
--create a program for dbms_scheduler to be used in jobs later
begin
DBMS_SCHEDULER.create_program (
program_name => 'test_sequence_do_inserts',
program_type => 'PLSQL_BLOCK',
program_action => q'[declare
last_id number;
max_id number := 1000000;
cnt_id number := 0;
e_stop exception;
pragma exception_init (e_Stop, -20022);
begin
for j in 1..max_id/10 loop
-- single insert for 10 rows
for i in 1..10 loop
insert into test_sequence_effects
values (test_sequence_normal.nextval -- ID_NORMAL
, test_sequence_scale.nextval -- ID_SCALABLE
, test_sequence_normal.nextval -- ID_REVERSE
)
returning id_normal into last_id;
cnt_id := cnt_id + 1;
if last_id >= max_id then
commit;
raise e_stop;
end if;
end loop;
commit;
-- pause for 1 sec
dbms_session.sleep(1);
end loop;
exception
when e_stop then
-- finish gracefully
dbms_output.put_line('This session inserted '||to_char(cnt_id)||' rows');
commit;
end;
]',
enabled => TRUE,
comments => 'Insert 10 rows, 1 sec pause.');
-- activate the program. This does not run the logic yet.
DBMS_SCHEDULER.enable (name => 'test_sequence_do_inserts');
end;
/
-- create multiple jobs
begin
for j in 1..100 loop
dbms_scheduler.create_job
(job_name => 'test_sequence_do_inserts_job'||to_char(j,'FM000'),
program_name => 'test_sequence_do_inserts',
start_date => systimestamp,
enabled => true);
dbms_scheduler.run_job (job_name => 'test_sequence_do_inserts_job'||to_char(j,'FM000'),
use_current_session => false);
end loop;
end;
/
After executing this script the scheduled job runs for quite some time.
We can check the number of rows in the table to see if it is finished.
select max(id_normal) last_value,count(*) row_count from test_sequence_effects;
other interesting selects to monitor the scheduled jobs
-- check scheduler jobs
select * from all_scheduler_programs;
select * from all_scheduler_jobs where job_name like 'TEST_SEQUENCE%';
select * from all_scheduler_running_jobs where job_name like 'TEST_SEQUENCE%';
select * from all_scheduler_job_log where job_name like 'TEST_SEQUENCE%';
select * from all_scheduler_job_run_details where job_name like 'TEST_SEQUENCE%';
And of cause the statistics need to be gathered
-- compute statistics for all indexes execute dbms_stats.gather_index_stats(user, 'TEST_SEQUENCE_NORMAL_IX',estimate_percent => 100); execute dbms_stats.gather_index_stats(user, 'TEST_SEQUENCE_SCALE_IX',estimate_percent => 100); execute dbms_stats.gather_index_stats(user, 'TEST_SEQUENCE_REVERSE_IX',estimate_percent => 100);
Index clustering factor
What is the clustering factor of an index? Essentially it tells us how good the index and the table data match. How many table blocks need to be read if each block is accessed via the index? The value itself needs to be compared with the number of blocks (min value) and rows (max value) in the table.
Here are some links that might improve your understanding of the clustering factor:
http://dbaparadise.com/2018/05/what-is-index-clustering-factor/
Ask Tom: https://asktom.oracle.com/pls/apex/f?p=100:11:0::::P11_QUESTION_ID:1032431852141
Blevel 3 break point
I run some further tests to see when the index based upon a scalable sequence will reach blevel3.
For a single session insert, blevel 3 was reached after approximately 38 million inserts.
INDEX_NAME BLEVEL LEAF_BLOCKS DISTINCT_KEYS CLUSTERING_FACTOR --------------------------- ------ ----------- ------------- ----------------- TEST_SEQUENCE_NORMAL_IX 2 81148 38200000 173362 TEST_SEQUENCE_REVERSE_IX 2 125912 38200000 38199995 TEST_SEQUENCE_SCALE_IX 3 129055 38200000 173362
For multiple sessions the same amount of blocks/leaf blocks should be reached earlier. However the distribution would be considerably more even. Both effects will partially cancel each other out. So far I didn’t measure it.