If you are like me and are using many workspaces, it is easy to get lost which workspace works on which host and I also tend to mix up/forget workspace names. The easy solution is to have bookmarks/favorites that store access to a specific workspace.
However this doesn’t work out of the box.
If the login page on the same host is called a second time, then the workspace name stays. This is implemented via a cookie (ORA_WWV_REMEMBER_UN in Apex 18+). The cookie stores the most recent workspace name and user name for a certain time. If you have several different workspaces under the same url, the cookie will only remember the last one. If you try to bookmark this url, then it will always show the most recent workspace not active one when you bookmarked it. And not even the last workspace might be remembered once you come back from vacation, because the cookie expired meanwhile.
APEX is written in APEX. We can use our knowledge about APEX urls, to set the correct workspace via url parameters.
solution
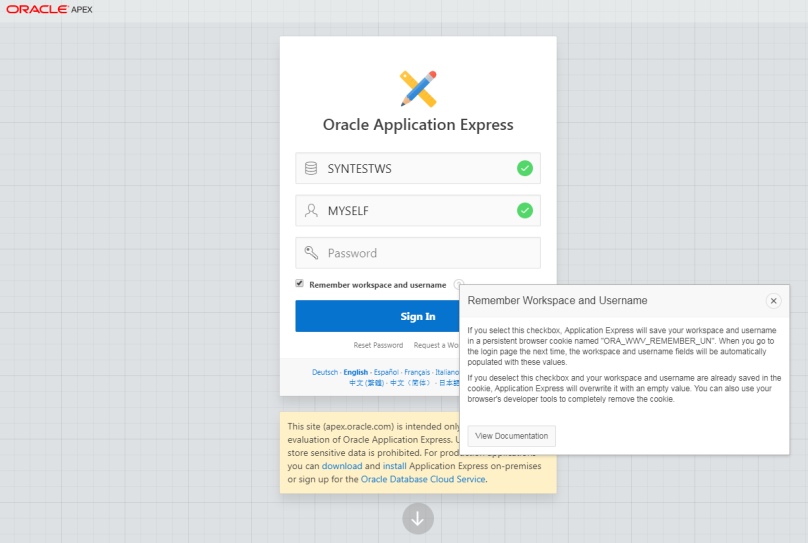
The login page for the internal apex application 4550 is page 1.
We can inspect the login page to find out about the correct item name.
The field with the workspace name is F4550_P1_COMPANY.
Simply supply the name of item and the value (=workspace name) like in any other apex application to the url.
Here is an example for apex.oracle.com. One of my workspace names is “SYNTESTWS”. And this will be the url, that I bookmark.
Also my Apex Quick Reference which sports APEX url syntax as a quick lookup tool and the next Syntegris 2019 calendar will feature Apex Urls. So try to get one of those during the next conferences (cu at DOAG 2018).
By Unknown – 1911 Ottoman calendar, Public Domain, Link
Calendar and date arithmetic is not easy. And not because of the database, but because the stuff exists in the real word. The database does an excellent job to reflect many or most of the strange attributes that calendar systems have.
Here is a collection of surprising, quirky or interesting things around usage of date and time values in an Oracle database. A lot of those things have nothing to do with the database, but instead with the complexity of the world.
By examining those edge cases we might learn something about the general workings of dates, calendars and the Oracle database.
5 Fun Facts
1) We live in the year 2561
alter session set nls_calendar = 'THAI BUDDHA';
select to_char(sysdate,'YYYY') as current_year from dual;
CURRENT_YEAR
2561
q.e.d.
Reason of cause is that there are other calendars out there in the world, not only the default Gregorian one. And according to the Thai Buddha calendar we are now in 2561.
2) persons existed that were born on the 30th of february
Why is 1753 the earliest date for datetime?
Good question. It is for historical reasons. In what we sometimes refer to as the western world, we have had two calendars in modern time: the Julian and the Gregorian calendars. These calendars were a number of days apart (depending on which century you look at), so when a culture that used the Julian calendar moved to the Gregorian calendar, they dropped from 10 to 13 days. Great Britain made this shift in 1752 (1752-09-02 were followed by 1752-09-14). An educated guess why Sybase selected 1753 as earliest date is that if you were to store an earlier date than 1753, you would also have to know which country and also handle this 10-13 day jump. So they decided to not allow dates earlier than 1753. Note, however that other countries did the shift later than 1752. Turkey, for instance, did it as late as 1927.
Being Swedish, I find it a bit amusing that Sweden had the weirdest implementation. They decided to skip the leap day over a period of 40 years (from 1700 to 1740), and Sweden would be in sync with the Gregorian calendar after 1740 (but meanwhile not in sync with anyone). However, in 1704 and 1708 the leap day wasn’t skipped for some reason, so in 1712 which was a leap year, they inserted yet an extra day (imagine being born in Feb 30!) and then did the shift over a day like everyone else, in 1753.
Does the database know about this? Lets find out:
alter session set nls_date_language='SWEDISH';
alter session set nls_territory='SWEDEN';
select to_date('30-02-1712','dd-mm-YYYY') from dual;
ORA-01839: date not valid for month specified
Using a date literal instead of TO_DATE doesn’t help either.
select to_char(date '1712-02-30') from dual;
ORA-01847: day of month must be between 1 and last day of month
So this doesn’t work. Why? Because the 30th of february only existed in the Julian Calendar System. The Oracle Database doesn’t support a Julian Calendar – we can not choose calendar systems, that are not in use anymore.
Btw. the 29th of februar 1712 does exist. Even in Sweden.
select to_char(date '1712-02-29','fmddth Month YYYY') from dual;
29th Februari 1712
The article also briefly mentioned that Turkey was the last country to switch to the Gregorian Calendar. Before that, they had the Rumi Calendar, which is a variation of Julian. It differs mostly about the starting year.
Turkey did the switch as late as 1927. After the 15th February 1332 AH (Rumi) they skipped 13 days, so that the next day was the 1st March 1927 AD (Gregorian). And they switched the year too.
Again, if we ask the database then it does not know about this gap.
set pagesize 100
alter session set nls_date_language='TURKISH';
alter session set nls_territory='TURKEY';
-- 28 days later...
with twentyeight as (select level lv from dual connect by level <=28)
select to_char(date '1927-02-10' + lv,'fmddth Month YYYY')
from twentyeight;
11th Şubat 1927
12th Şubat 1927
13th Şubat 1927
14th Şubat 1927
15th Şubat 1927
16th Şubat 1927
17th Şubat 1927
18th Şubat 1927
19th Şubat 1927
20th Şubat 1927
21st Şubat 1927
22nd Şubat 1927
23rd Şubat 1927
24th Şubat 1927
25th Şubat 1927
26th Şubat 1927
27th Şubat 1927
28th Şubat 1927
1st Mart 1927
2nd Mart 1927
3rd Mart 1927
4th Mart 1927
5th Mart 1927
6th Mart 1927
7th Mart 1927
Since the leaped days existed in the Gregorian Calendar, there is no reason to leave them out.
Interestingly in Turkey there should still be living persons that were born in or before 1332!
(older than 92 years)
3) There are no days between 4 Oct 1582 and 15 Oct 1582
select to_char(date '1582-10-4','ddth Mon YYYY') from dual;
04th Oct 1582
+1 day
select to_char(date '1582-10-4' + 1,'ddth Mon YYYY') from dual;
15th Oct 1582
04th Oct 1582 + 1 = 15th Oct 1582 ?
After the previous chapter the reason should be obvious.
At this time the Gregorian calendar leapt 10 days in order to catch up with the astronomical year.
year (a or y or yr) [2]
a traditional unit of time usually equal to 365 or 366 days. We need a whole number of days for the calendar year used in ordinary life. Ancient astronomers knew that the year [1] is approximately 365 days long, and we now know the correct figure is approximately 365.242 days. If we use 365 as the number of days in every calendar year, the extra 0.242 day adds up quickly and causes large errors in predicting the seasons. To solve this problem, the Roman emperor Julius Caesar decreed in 46 BC that the calendar year should have 365 days generally, but that every fourth year should have an extra, or 366th, day. The longer year is called a leap year. In this Julian calendar, four years equal exactly 1461 days, so the average Julian year is exactly 365.25 days.
This was a big step toward accuracy in the calendar, but the Julian year is too long by 0.008 day, or a little over 11 minutes. By the time of the Renaissance, these 11-minute errors had accumulated to a total error of about 10 days (since the Council of Nicaea in 325 AD, which set the rules for deciding when Easter should be celebrated). The spring equinox was occurring near March 11 instead of March 21. In 1582, Pope Gregory XIII decreed that 10 days should be dropped from the calendar: the day after 1582 October 4 was October 15. To reduce future errors, the pope further decreed that years divisible by 100 are not leap years unless they are also divisible by 400. Thus 2000 and 2400 are leap years, but 2100, 2200, and 2300 are not. It took many years, but the Gregorian calendar has now been accepted as the civil calendar in all countries of the world.
With the Gregorian adjustment, there are exactly 146 097 days in every 400 years, and the average Gregorian year is exactly 365.2425 days. The Gregorian year is still too long, but by less than half a minute. It will take thousands of years for this error to accumulate to 1 day, so the calendar year and the tropical year are in good enough agreement to last us a long time.
And this time, the database with its default Gregorian calendar knows about it!
Database considers days that seem to be inside this gap, as if they were after the leaped days.
select to_char(date '1582-10-5','ddth Mon YYYY') from dual;
15th Oct 1582
4) The north pole and the south pole are on different time zones
In the poles, the time is UTC in the North Pole and UTC+12 in the South Pole.
(and no this is not the “South Pole, Illinois, USA” nor the “North Pole, New South Wales, Australia”)
So in case you happen to live or work at the south pole, set your session time zone to UTC+12.
Let me simulate that for you:
col sessiontimezone format A20
col dbtimezone format A20
-- check current settings
select sessiontimezone, tz_offset(sessiontimezone),
dbtimezone, tz_offset(dbtimezone)
from dual;
Currently I’m in Frankfurt which is the same time zone as Berlin, so 2 hours before UTC.
Since I have to do some quick work at the south pole, let’s change my session settings to reflect that.
-- change to UTC+12
alter session set time_zone ='+12:00';
Session altered.
-- how late is it here currently?
select sysdate, current_date from dual;
It is good to be back! Timezone travelling is exhausting.
5) The word calendar comes from the Latin word Kalendae which meant the first day of the month
A calendar is essentially a list of first month days.
Getting the first day of a month is easy.
trunc(sysdate,'MM') => 1st of the current month.
But what about the first day of a week? And which week are we in?
This is complex for two major reasons. There is quite some confusion about when does a week start and what is the first week in the year. And with confusion I mean, different countries have different rules for that.
The good thing is, the Oracle database has all this knowledge. A developer just has to understand it. As usual NLS settings will influence the behaviour.
Different date formats refer to those NLS settings.
‘D’ returns the number of the day inside the week.
‘WW’ returns the number of the week inside the year. Week 1 starts on the first day of the year and continues to the seventh day of the year.
‘IW’ returns the number of the ISO-week.
‘YYYY’ refers to the year
‘IYYY’ refers the ISO-year.
some examples
What weekday is the first day of the week?
NLS_TERRITORY influences what the first day of a week is.
alter session set NLS_DATE_LANGUAGE = 'AMERICAN';
alter session set NLS_TERRITORY = 'AMERICA';
select to_char(trunc(sysdate,'D'),'Day') as "First Day in America" from dual;
alter session set NLS_TERRITORY = 'GERMANY';
select to_char(trunc(sysdate,'D'),'Day') as "First Day in Germany" from dual;
alter session set NLS_TERRITORY = 'IRAQ';
select to_char(trunc(sysdate,'D'),'Day') as "First Day in Iraq" from dual;
select to_char(trunc(sysdate,'IW'),'Day') as "ISO First Day" from dual;
result
Session altered.
Session altered.
First Day in America
---------
Sunday
Session altered.
First Day in Germany
---------
Monday
Session altered.
First Day in Iraq
---------
Saturday
ISO First Day
---------
Monday
NLS_TERRITORY does not directly influence what the first week in the year is! To get the week we always use formatter options (IW or WW) that directly decide, which week logic needs to be applied.
However NLS_TERRITORY sets an ISO-Week flag. Unfortunately this is not well documented. I believe this flag is partially responsible for one of the behaviours mentioned in the “Stranger Things” section.
5 Stranger Things – bug or feature?
1) sysdate returns a date, but systimestamp does not return a timestamp
systimestamp returns a timestamp with timezone. Localtimestamp would be the function that returns a timestamp. In many cases systimestamp still is the best option to use!
These are the DATATYPES : pseudocolumns dealing with points in time.
DATE : sysdate, current_date
TIMESTAMP : localtimestamp
TIMESTAMP WITH TIME ZONE : systimestamp, current_timestamp
TIMESTAMP WITH LOCAL TIME ZONE
example
First modify the session so that session timezone and db timezone differs.
ALTER SESSION SET TIME_ZONE='+10:00';
show nls
DB_TIMEZONE +01:00
SESSION_TIMEZONE +10:00
SESSION_TIMEZONE_OFFSET +10:00
Check the pseudocolumns and convert them to timestamp if needed (using cast). The same would happen when the value is stored in a timestamp column. The database implicitly does the conversion.
select to_char(sysdate,'DD-MM-RR HH24:MI:SS') as "sysdate",
to_char(localtimestamp,'DD-MM-RR HH24:MI:SS') as "localTS",
to_char(current_timestamp,'DD-MM-RR HH24:MI:SS TZH') as "currentTS",
to_char(systimestamp,'DD-MM-RR HH24:MI:SS TZH') as "sysTS",
to_char(cast(current_timestamp as timestamp),'DD-MM-RR HH24:MI:SS') as "currentTS_converted",
to_char(cast(systimestamp as timestamp),'DD-MM-RR HH24:MI:SS') as "sysTS_converted"
from dual;
Note that localtimestamp and current_timestamp returns (and stores) a different hour than sysdate. Systimestamp returns the same hour after conversion and therefore matches sysdate.
Better would be to have a column that stores the timezone information too. Either timestamp with time zone or timestamp with local time zone. Since TZ info is stored, it does not matter anymore which datatype has the source.
select to_char(sysdate,'DD-MM-RR HH24:MI:SS') as "sysdate",
to_char(localtimestamp,'DD-MM-RR HH24:MI:SS') as "localTS",
to_char(current_timestamp,'DD-MM-RR HH24:MI:SS TZH') as "currentTS",
to_char(systimestamp,'DD-MM-RR HH24:MI:SS TZH') as "sysTS",
to_char(cast(localtimestamp as timestamp with local time zone),'DD-MM-RR HH24:MI:SS [TZR]') as "localTS_converted",
to_char(cast(current_timestamp as timestamp with local time zone),'DD-MM-RR HH24:MI:SS [TZR]') as "currentTS_converted",
to_char(cast(systimestamp as timestamp with local time zone),'DD-MM-RR HH24:MI:SS [TZR]') as "sysTS_converted"
from dual;
As we can see the result is always the same point In Time.
2) Micro Intervals
And of cause there are also datatypes that deal with durations.
NUMBER
INTERVAL YEAR TO MONTH
INTERVAL DAY TO SECOND
Why are there two interval types? Because those are independend measurement systems for a duration of time. And there is no correct conversion possible from one into the other.
Consider this: 29 days (interval day to second) could be slightly less, slightly more or sometimes even exactly one 1 month (interval year to month). We can only do this conversion if we additionally have some reference point, like the starting day. Without this reference point in time, we can’t correctly convert from one system of measurement into the other.
We can convert from number to interval using the functions numtoDSinterval or numtoYMinterval.
Let’s do some workday calculations.
My typical day of work is from (ok I might understate a bit) is from 9:30 to 18:30.
select to_date('18:30','HH24:MI') - to_date('9:30','HH24:MI') from dual;
0.375
A date minus a date returns a number. This is the result in days. So I worked for 0.375 days. Lets see that in interval format.
select numtoDSinterval(0.375, 'day') from dual;
+00 09:00:00.000000
Looks about right!
Can we also see that in a Month interval ? The MONTHS_BETWEEN functions gives us the result in number (= months) for the difference between two dates.
select months_between(to_date('19:30','HH24:MI')
,to_date('10:30','HH24:MI'))
from dual;
0
Hm… 9 hours equal 0 months…
Let’s assume somebody has a large shift requiring to work for more than 24 hours.
-- how many months did he work?
select months_between(to_date('2018-07-02 19:30','YYYY-MM-DD HH24:MI')
,to_date('2018-07-01 07:15','YYYY-MM-DD HH24:MI'))
from dual;
0.0487231182795698924731182795698924731183
And as an interval…
select numtoYMinterval(0.0487, 'MONTH') from dual;
+00-01
Hmm… 0.0488 Months => 0 Years 1 Month ?
Is it always rounded up?
So what would a larger result be:
select numtoYMinterval(1.0487, 'MONTH') from dual;
For very small values (0.01-0.49) numtoYMinterval rounds up, instead of rounding down. For larger values, the rounding is consistent. Those values are rounded down, as expected.
This feature was implemented somewhere between Oracle DB version 10 and 11. It took me a while, but now it is accepted as a unpublished bug (26244914).
Recommendation: Avoid numtoYMinterval. There are several strange edge cases with that function.
3) date format “J” – Julian
We can use the J format mask to spell out numbers (Jsp).
J is called Julian day; the number of days since January 1, 4712 BC.
Let’s play around with it a little.
select to_char(sysdate,'J') from dual;
2458317
Of cause when you execute it, you will get a different (larger) number. Time passed.
We use this number and substract it from sysdate, then add the number of days we are interested in. This time using “sp” = spelling in the format parameter.
select to_char((sysdate-(2458317-5)),'Jsp') from dual
Five
Cool! This way we can spell out any number. Unfortunatly this only works in English, not in other languages.
Important side note: The calculation must be like this
sysdate-(2458317-5)
Although mathematically the same, this would have resulted in an error
(sysdate-2458317)+5
ORA-01841: (full) year must be between -4713 and +9999, and not be 0
Problem is that the resulting date value is invalid (before the beginning of time).
To avoid hardcoding 2458317, we can calculate it from sysdate.
select to_char(sysdate-(to_number(to_char(sysdate,'J'))-123),'Jsp') spell_number from dual;
One Hundred Twenty-Three
Ok let’s try a large number…
select to_char(sysdate-(to_number(to_char(sysdate,'J'))-1721116),'Jsp') spell_number from dual
One Million Seven Hundred Twenty Thousand Seven Hundred Fifty-One
And one more…
select to_char(sysdate-(to_number(to_char(sysdate,'J'))-1721117),'Jsp') spell_number from dual
Wat!? So spelling out One Million Seven Hundred Twenty Thousand Seven Hundred Fifty-One is ok, but One Million Seven Hundred Twenty Thousand Seven Hundred Fifty-Two not…
Hold on a minute. Even the first number was not spelled correctly!
1721116 != One Million Seven Hundred Twenty Thousand Seven Hundred Fifty-One
As so often there is a reason for that. The difference between both numbers is exactly 365. Which is our first clue. We need to understand which dates are we talking about.
The following rows depend heavily on the database version it is running.
This is from a 12.2.0.1 DB. For readability, I removed several hundred rows from the output.
with testdata as (select level lv, 1721340-300+level days# from dual connect by level <= 400)
select lv, days#,
to_char(sysdate-(to_number(to_char(sysdate,'J'))-days#),'YYYY-MM-DD A.D.') dy,
to_char(sysdate-(to_number(to_char(sysdate,'J'))-days#),'J') Julian,
to_char(sysdate-(to_number(to_char(sysdate,'J'))-days#),'Jsp') spelled_number
from testdata;
LV DAYS# DY JULIAN SPELLED_NUMBER
1 1721041 0001-12-15 B.C. 1721041 One Million Seven Hundred Twenty-One Thousand Forty-One
2 1721042 0001-12-16 B.C. 1721042 One Million Seven Hundred Twenty-One Thousand Forty-Two
3 1721043 0001-12-17 B.C. 1721043 One Million Seven Hundred Twenty-One Thousand Forty-Three
4 1721044 0001-12-18 B.C. 1721044 One Million Seven Hundred Twenty-One Thousand Forty-Four
5 1721045 0001-12-19 B.C. 1721045 One Million Seven Hundred Twenty-One Thousand Forty-Five
6 1721046 0001-12-20 B.C. 1721046 One Million Seven Hundred Twenty-One Thousand Forty-Six
7 1721047 0001-12-21 B.C. 1721047 One Million Seven Hundred Twenty-One Thousand Forty-Seven
8 1721048 0001-12-22 B.C. 1721048 One Million Seven Hundred Twenty-One Thousand Forty-Eight
9 1721049 0001-12-23 B.C. 1721049 One Million Seven Hundred Twenty-One Thousand Forty-Nine
10 1721050 0001-12-24 B.C. 1721050 One Million Seven Hundred Twenty-One Thousand Fifty
11 1721051 0001-12-25 B.C. 1721051 One Million Seven Hundred Twenty-One Thousand Fifty-One
12 1721052 0001-12-26 B.C. 1721052 One Million Seven Hundred Twenty-One Thousand Fifty-Two
13 1721053 0001-12-27 B.C. 1721053 One Million Seven Hundred Twenty-One Thousand Fifty-Three
14 1721054 0001-12-28 B.C. 1721054 One Million Seven Hundred Twenty-One Thousand Fifty-Four
15 1721055 0001-12-29 B.C. 1721055 One Million Seven Hundred Twenty-One Thousand Fifty-Five
16 1721056 0001-12-30 B.C. 1721056 One Million Seven Hundred Twenty-One Thousand Fifty-Six
17 1721057 0001-12-31 B.C. 1721057 One Million Seven Hundred Twenty-One Thousand Fifty-Seven
18 1721058 0001-01-01 B.C. 1720693 One Million Seven Hundred Twenty Thousand Six Hundred Ninety-Three
19 1721059 0001-01-02 B.C. 1720694 One Million Seven Hundred Twenty Thousand Six Hundred Ninety-Four
20 1721060 0001-01-03 B.C. 1720695 One Million Seven Hundred Twenty Thousand Six Hundred Ninety-Five
21 1721061 0001-01-04 B.C. 1720696 One Million Seven Hundred Twenty Thousand Six Hundred Ninety-Six
22 1721062 0001-01-05 B.C. 1720697 One Million Seven Hundred Twenty Thousand Six Hundred Ninety-Seven
23 1721063 0001-01-06 B.C. 1720698 One Million Seven Hundred Twenty Thousand Six Hundred Ninety-Eight
24 1721064 0001-01-07 B.C. 1720699 One Million Seven Hundred Twenty Thousand Six Hundred Ninety-Nine
25 1721065 0001-01-08 B.C. 1720700 One Million Seven Hundred Twenty Thousand Seven Hundred
... snip 1721066-1721112 no major change there...
73 1721113 0001-02-25 B.C. 1720748 One Million Seven Hundred Twenty Thousand Seven Hundred Forty-Eight
74 1721114 0001-02-26 B.C. 1720749 One Million Seven Hundred Twenty Thousand Seven Hundred Forty-Nine
75 1721115 0001-02-27 B.C. 1720750 One Million Seven Hundred Twenty Thousand Seven Hundred Fifty
76 1721116 0001-02-28 B.C. 1720751 One Million Seven Hundred Twenty Thousand Seven Hundred Fifty-One
77 1721117 0000-00-00 0000 0000000 000000000000000000000000000000000000000000000000000000000000000000000000000000
78 1721118 0001-03-01 B.C. 1720752 One Million Seven Hundred Twenty Thousand Seven Hundred Fifty-Two
79 1721119 0001-03-02 B.C. 1720753 One Million Seven Hundred Twenty Thousand Seven Hundred Fifty-Three
80 1721120 0001-03-03 B.C. 1720754 One Million Seven Hundred Twenty Thousand Seven Hundred Fifty-Four
... snip 1721120-1721420 no major change there...
381 1721421 0001-12-29 B.C. 1721055 One Million Seven Hundred Twenty-One Thousand Fifty-Five
382 1721422 0001-12-30 B.C. 1721056 One Million Seven Hundred Twenty-One Thousand Fifty-Six
383 1721423 0001-12-31 B.C. 1721057 One Million Seven Hundred Twenty-One Thousand Fifty-Seven
384 1721424 0001-01-01 A.D. 1721424 One Million Seven Hundred Twenty-One Thousand Four Hundred Twenty-Four
385 1721425 0001-01-02 A.D. 1721425 One Million Seven Hundred Twenty-One Thousand Four Hundred Twenty-Five
386 1721426 0001-01-03 A.D. 1721426 One Million Seven Hundred Twenty-One Thousand Four Hundred Twenty-Six
387 1721427 0001-01-04 A.D. 1721427 One Million Seven Hundred Twenty-One Thousand Four Hundred Twenty-Seven
388 1721428 0001-01-05 A.D. 1721428 One Million Seven Hundred Twenty-One Thousand Four Hundred Twenty-Eight
389 1721429 0001-01-06 A.D. 1721429 One Million Seven Hundred Twenty-One Thousand Four Hundred Twenty-Nine
390 1721430 0001-01-07 A.D. 1721430 One Million Seven Hundred Twenty-One Thousand Four Hundred Thirty
391 1721431 0001-01-08 A.D. 1721431 One Million Seven Hundred Twenty-One Thousand Four Hundred Thirty-One
392 1721432 0001-01-09 A.D. 1721432 One Million Seven Hundred Twenty-One Thousand Four Hundred Thirty-Two
393 1721433 0001-01-10 A.D. 1721433 One Million Seven Hundred Twenty-One Thousand Four Hundred Thirty-Three
394 1721434 0001-01-11 A.D. 1721434 One Million Seven Hundred Twenty-One Thousand Four Hundred Thirty-Four
395 1721435 0001-01-12 A.D. 1721435 One Million Seven Hundred Twenty-One Thousand Four Hundred Thirty-Five
396 1721436 0001-01-13 A.D. 1721436 One Million Seven Hundred Twenty-One Thousand Four Hundred Thirty-Six
397 1721437 0001-01-14 A.D. 1721437 One Million Seven Hundred Twenty-One Thousand Four Hundred Thirty-Seven
398 1721438 0001-01-15 A.D. 1721438 One Million Seven Hundred Twenty-One Thousand Four Hundred Thirty-Eight
399 1721439 0001-01-16 A.D. 1721439 One Million Seven Hundred Twenty-One Thousand Four Hundred Thirty-Nine
400 1721440 0001-01-17 A.D. 1721440 One Million Seven Hundred Twenty-One Thousand Four Hundred Forty
Two strange things to observe. If we look closely we can see that the year 1 BC repeats itself two times. For example line 17 and line 383 both show the 31st of December 1 BC. I now say 1 BC[1] and 1 BC[2] to distinguish the entries for those years. Second observation is that the 29th of February 1 BC[2] exists and is kind of undefined (0000-00-00 0000 0000000). The 29th of februar in year 1 BC[1] does not exist in the data. This is not shown in the sample set, but you can easily modify the query to see for yourself.
In older DB versions the second 1 BC occurence would be year 0. For which some of the date functions also return the error message
ORA-01841: (full) year must be between -4713 and +9999, and not be 0
I believe that there was some half baked bug fix at oracle. Year 0 was aliased as Year 1 BC. This also explains, why there seems to be a leap day. Year 0 would have a leap day according to the logical rules (as defined by Pope Gregory XIII). In older database versions any day from the year 0 resulted in 0000-00-00 0000. Which also created problems. Fortunatly the issue only seems to appear when playing around with the J(ulian) format. And even then only for some very large values. The chance to get bugs in real world systems is extremly slim.
some more examples Date based comparison
select case when 1721057 = 1721423
then 'equal' else 'unequal' end as "check"
from dual;
unequal
As expected those two numbers are not equal.
Compare the same numbers, but added to the same date.
select case when to_date('01-01-4712 BC','DD-MM-YYYY AD') + 1721057
= to_date('01-01-4712 BC','DD-MM-YYYY AD') + 1721423
then 'equal' else 'unequal' end as "check"
from dual;
equal
Now they are equal.
consecutive day check
Negative years within a date literal are BC years. Here follows a shot list of small date calculations around the problematic years and days.
select to_char(date '-0001-12-31','DD-Mon-YYYY AD') from dual;
31-Dec-0001 BC
select to_char(date '-0001-12-31' + 1,'DD-Mon-YYYY AD') from dual;
01-Jan-0001 AD
31-Dec-0001 BC + 1 = 01-Jan-0001 AD
select to_char(date '-0001-01-01' - 1,'DD-Mon-YYYY AD') from dual;
31-Dec-0002 BC
01-Jan-0001 BC – 1 = 31-Dec-0002 BC
select to_char(date '-0002-12-31' + 1,'DD-Mon-YYYY AD') from dual;
01-Jan-0001 BC
31-Dec-0002 BC + 1 = 01-Jan-0001 BC
select to_char(date '-0001-02-28' + 1,'DD-Mon-YYYY AD') from dual;
01-Mar-0001 BC
28-Feb-0001 BC = 01-Mar-0001 BC
Seems about right.
At least here Oracle adhers to ISO 8601 regulation “every date must be consecutive”.
And some more edge cases
select to_char(date '-4712-1-1','YYYY A.D.') from dual;
4712 B.C.
select to_char(date '-1000000','YYYY A.D.') from dual;
ORA-01841: (full) year must be between -4713 and +9999, and not be 0
So there is no 1 Million Years B.C. in the Oracle DB.
4) The first ISO-year day for 1st Januar 2021 is in 2019
select to_char(trunc(date '2021-01-01','IYYY'),'YYYY-MM-DD') from dual;
2019-12-30
Now this looks strange! It happens in all supported DB versions.
According to the docs IYYY is a supported format model for TRUNC. It is specified as “Year containing the calendar week, as defined by the ISO 8601 standard“.
Note that the doc mentions the calendar week. The 1st Januar 2021 is in calendar week (IW) 53. That week still is part of year 2020. And the first day (Monday) of the first ISO week of 2020 is 30th of December 2019.
So it seems as if
TRUNC(:date,'IYYY')
really does:
TRUNC(
TRUNC(
TRUNC(:date,'IW') -- first day of the iso-week
,'YEAR') -- first day of the calendar YEAR regardless of iso
,'IW') -- first day of iso-week
I think this is illogical behaviour and as such should be considered a bug. However it is correct in terms of the ISO 8601 – which calls it the “ISO week-numbering year”. So most likely it will not be fixed.
Remember: Always truncate useing ‘YEAR’ or ‘YYYY’, never use ‘IYYY’ it is just to confusing.
5) lateral SQL injection
Consider the following code. Is it safe?
create or replace procedure date_proc(p_date in date) is
stmt varchar2(200);
res varchar2(100);
begin
stmt:='select object_name from all_objects where created = ''' || p_date ||'''';
dbms_output.enable;
dbms_output.put_line(stmt);
execute immediate stmt into res;
dbms_output.put_line('result:'||res);
exception
when no_data_found then
dbms_output.put_line('result: no objects found');
end;
/
set serveroutput on
execute date_proc(sysdate);
Dynamic sql is always at risk for sql injection. However since that code makes sure the value is a correct date it doesn’t seem possible to tamper with the code.
This is just some demo code. It has other issues as well (like removing time from the input).
Afaik David Litchfield was the first to describe the potential security issue with this. He called it the Lateral SQL injection. I prefer the name SQL injection by NLS.
Consider the following NLS setting. Any client can modify its NLS environment.
alter session set nls_date_format = 'DD/MM/YYYY"'' or 1=1"--';
Then run the statement again!
set serveroutput on
execute date_proc(sysdate);
select object_name from all_objects where created = '16/07/2018 ' or 1=1--'
ORA-01422: exact fetch returns more than requested number of rows
Ok this happens, because the code doesn’t expect multiple rows to be returned. We can modify that.
alter session set nls_date_format = 'DD/MM/YYYY"'' or 1=1 and rownum=1"--';
Fortunatly the possibilites via NLS format are limited. For example the length of the injected code can only be very small. When trying more complex modifications we get
ORA-01801: date format is too long for internal buffer
However sometimes this can potentially be used as a first step for more serious hacking.
A similar exploit is possible using the NUMBER datatype (via nls_numeric_characters).
The more interesting question is, how to correct code like this.
One option is to use bind variables.
create or replace procedure date_proc(p_date in date) is
stmt varchar2(200);
res varchar2(100);
begin
stmt:='select object_name from all_objects where created = :dat';
dbms_output.enable;
dbms_output.put_line(stmt);
execute immediate stmt into res using p_date ;
dbms_output.put_line('result:'||res);
exception
when no_data_found then
dbms_output.put_line('result: no objects found');
end;
/
Other options include validating any concatenated input for example by using dbms_assert.
Conclusion
Calendars are difficult. Oracle implemented calendar functionality very thoroughly.
It is the duty of a developer/DBA to understand the complexities around calendars, time zones, time conversions and Time Machines.
This post intents to help you with the decision, if it is about time to upgrade. And if you are on the new version already, then you might find out about some new features that you might not have noticed so far.
I recently upgraded from version 17.3 to 18.2.
Here is a listing of my favourite changes. This listing includes new features, changed behaviours but also fixed bugs in either version 18.1 or 18.2. It is totally subjective. The focus is on SQL Developer only, I didn’t analyze changes regarding SQL Data Modeler, sqlcl or ORDS.
TL;DR;
Upgrade Now? => Yes!
Links
If you want you can go through the various documents of new features and bugfixes yourself.
It is very likely you disabled the welcome page in a previous version. Go to Help/Start Page to show it. Then you can decide to keep it around by checking the appropriate check box in the lower left corner.
In the past this welcome screen was essentially useless. Now it has a section “RECENT” connections. It holds the list of the last five recently opend connections which I find myself using a lot.
The welcome screen still has a lot that can be improved (in red is what I dislike). But now it is a working and useful part of the tool.
Also interesting is the DEMO tab in the “Getting Started” section. Among others it links to videos about “Debugging PLSQL”, “Importing Data from Excel” and “Introduction to Oracle SQLcl”.
Improved Editor / Syntax Highlighting
Syntax Highlighting is arguably one of the most crucial features of any IDE.
A lot of bugfixes have been done for that.
Here is a quick list of changes/bugfixes with regards to the editor or syntax highlighting. The list is not complete.
Improved Arbori Editor:
syntax error highlighting
catch syntax errors before Arbori execution
Change Case as You Type was removed from the Code Insight Preferences page. Use the Code Formatter to set your identifier and keyword preferences, and format your code on demand instead.
SQL Injection vulnerability warnings for your PL/SQL
27678178 PARSER DOESN’T LIKE NEW FOR CALLING A USERDEFINED CONSTRUCTOR IN A SQLBLOCK
27718434 FORUM: SOME KEYWORDS ARE HIGHLIGHTED ONLY WHILE TYPING
27803006 FORUM: BRACES () COLORING IS INTERMITTENT AND DIFFERENT FROM PREFERENCES
27939025 FORUMS: BETTER PL/SQL SYNTAX HIGHLIGHTING/FORMATTER FOR CONDITIONAL COMPILATION SYNTAX
Since I use conditional compiling a lot in PLSQL the last fix is an essential one for me.
SQL Injection detection is a very promising feature. Especially when working with not so experienced developers. They easily might overlook some SQL injection issue and now the editor is able to warn about such scenarios. Jeff explains more about it here.
Btw: “Arbori” refers to the language used to describe parse trees during syntax analysis. Want to know more?
DBA Users Editor – SQL page now generates complete DDL for user including GRANTS
Way overdue. Happens a lot that you want a script to create the same schema that you have in some DEV environment and now you want to script the user creation for TEST and potentially PROD environments.
In the past the grants had been missing. A quick test of mine showed that all the grants that this schema needs seem to be there now. Granted roles, object privs, granted access to directory objects, granted system privileges. However grants that are given to other users are not included! So it is still not complete.
And remember, there also is a “create like” feature in the DBA panel.
This “create like” has not all the grants that are on the DBA Users Editor SQL Page.
27169586 ALTER SCRIPT SCROLLS OFF PAGE, IMPOSSIBLE TO READ WITHOUT MUCH SCROLLING/RESIZE
I’m not sure, but I think I hit this bug very often in the past. And then it was annoying as hell. However we can’t access the bug numbers, so I’m not sure if that fix covers the problematic behaviour that I remember. At least it looks as if it is fixed now. Will monitor it closely.
Improved Code Formatter
I’m not a big fan of code formatters. But I know those matters to many developers. The bugfix lists are full of minor changes to it.
Two things I would like to point out:
Formatter: New Basic Preference: Convert Case Only
This new setting means, the code will not be reorganized. Only the UPPER/lower case logic is applied. I personally like to have everything in lowercase (apart from some plsql method names where I use lowerCamelCase). So this setting allows me to quickly format SQL statements in the worksheet.
FORUM – ADDED FORMATTER OPTION: RIGHT-ALIGN QUERY KEYWORDS
I know that many developers like to format their SQL queries in such a way, that the keywords are right alined. So this is possible now.
Example Result
-- left alined keywords
select containerid
,status
,reason
,additional_info
from table1 t1
left join table2 t2 on t1.id = t2.id
where barcode = :barcode;
-- right alined keywords
select containerid
,status
,reason
,additional_info
from table1 t1
left join table2 t2 on t1.id = t2.id
where barcode = :barcode;
Interesting new features or bugfixes
The following features are less deciding. So they might not be the sole reason why you want to upgrade. However they might be useful to know and to try out eventually.
Can now convert Oracle to ANSI Joins with context menu
This feature sounds very promising. Unfortunatly I didn’t find the context menu yet, that allows to do so. So far I tried it only on a 11.2.0.4 db. Maybe the option uses functionality that requires a higher db version.
DBMS_XPLAN Added to Explain Drop Down toolbar menus
The new option does not create a plan immediatly. Instead it finds the sql_id and then produces a statement that uses the sql_id and then can read the execution plan using DBMS_XPLAN.
select *
from table(dbms_xplan.display_cursor(
sql_id=>'d7yr3jw0rj963',
format=>'ALLSTATS LAST'));
DBMS_XPLAN is the best way to get a nicely formatted execution plan.
Enhanced DB Search for dependencies and selected object types
It is not clear what was enhanced. The search menu certainly looks the same. Also the search findings didn’t really seem to change.
In case you don’t know, but search does cover view sources. This was already implemented a few versions ago.
I use the DB Search a lot. And I welcome any improvements in that area, even if I don’t see them at first glance.
ORDS 18.2 bundled
Tools/REST Data Services
Extract variable/function prototype
Refactoring code is something that SQL Developer supports since many versions now. It is surprising that almost no developers know about it or even use that frequently.
This new option allows to quickly change expressions into local functions. This can save an aweful lot of codeing time!
Example
Somewhere inside my plsql code I have a concatenation.
...
begin
...
if v_json is not null then
p_plate.additional_info := '{'||v_json||'}';
end if;
...
I mark the '{'||v_json||'}' part, open the right context menu, choose Refactoring / Extract Variable/Function/CTE and give the function a new name, for example make_json_object.
The result is that my procedure got a local function. And the marked expression is replaced with a call to that function.
...
--refactored function
function make_json_object(v_json clob) return varchar2 is
begin
return '{'||v_json||'}';
end make_json_object;
begin
...
if v_json is not null then
p_plate.additional_info := make_json_object(v_json);
end if;
...
The code would still require some rework, but it is a nice quick starting point.
As always you can undo that change using CTRL-Z.
Allow explain/autotrace on selected text
This I like a lot. You can mark a part of a bigger sql statement and get the explain plan for that part only. The marked code needs to be a valid SQL statement of cause.
Highly useful for with clause statements. But also for expanded SQL queries.
27962558 DRAG AND DROP FROM GRID TO EDITOR SHOULD QUOTE STRINGS
The behaviour for drag and drop changed. I’m not so convinced about it, but I rarely use drag and drop from the grid.
If we drag from a single varchar2 column, then all the values are copied, put in single quotes and separated by comma.
However if we copy from multiple columns then the strings are not quoted.
The quoteing only happens during drag and drop. Not when copying with CTRL+C, CTRL+V.
I think this feature can be highly helpful, but needs some getting used to it.
Conclusion
There are several more changes, but those are the ones I am most interested in. As with any new toy we should check what is possible and how we can use it to improve our playing codeing experience.
Several of the new features are so convincing to me that I installed SQL Developer 18.2 now in all projects that I supervise.
Feel free to share what new features or bugfixes you like most!
A recent question on otn asked how to access a plsql collection using multiple keys.
It is a typical scenario to build a second collection, to be able to access the main data in the first collection. The second collection fulfills the same role as an index on a table. It allows fast access to the main data record. I usually call the second collection an “index collection”.
But the forum question was not how to do a simple key => value lookup, but instead have two keys (based upon record set values) and use them to access the main collection.
solution
There are two general ways.
Combine the keys into a single key or build a nested collection. I will show a quick example for both ways.
Way 1) Combined key
We can consolidate the two keys into one single key. Typically using some delimiter. And then use that combined key for the index_collection.
combinedKey := key1||':'||key2;
Of cause we need to make sure the delimiter is some value that does not exist in any of the keys.
Example
If you try to copy and run this example please note that the syntax highlighter removed the label “build_index”
You might want to add this again, just after the “– index data” comment.
set serveroutput on
declare
cursor c is (select trunc((level+2)/3) lvkey, chr(ASCII('A')+mod(level*2,3)) letter, round(dbms_random.value(1,100)) val
from dual
connect by level <=10
);
type tabdata_t is table of c%rowtype index by binary_integer;
tabdata tabdata_t;
type keylookup_t is table of binary_integer index by varchar2(100);
keylookup keylookup_t;
begin
-- load data
open c;
fetch c
bulk collect into tabdata; -- notice no limit clause here. For larger record sets you need to use a loop and LIMIT!
close c;
-- index data
<>
for i in 1..tabdata.count loop
keylookup(to_char(tabdata(i).lvKey)||':'||tabdata(i).letter) := i;
end loop build_index;
-- index is now complete.
-- Test the index first
dbms_output.put_line('Index 1B=>'|| to_char(keylookup('1:B')));
dbms_output.put_line('Index 3A=>'|| to_char(keylookup('3:A')));
-- now fetch the data using the index
dbms_output.put_line('Data 1B=>'|| tabdata(keylookup('1:B')).val);
dbms_output.put_line('Data 3A=>'|| tabdata(keylookup('3:A')).val);
end;
/
Output
Index 1B=>2
Index 3A=>9
Data 1B=>32
Data 3A=>67
PL/SQL procedure successfully completed.
Way 2) collection of collection
A collection can be part of another collection. Nesting collections means we could do a lookup using two (or more) key values where each key is used for one collection.
lookup(key1) => col2
this returns a collection (e.g. col2). We can access the elements of the collection using the second key.
col2(key2) => element
or the short form: lookup(key1)(key2) => element
For readability we could add a record layer in between, but that is not neccessary. lookup(key1).list(key2) => element
Example
Notice the definition of the index collection is in line 14 with the matching type definitions in line 11 and 12.
set serveroutput on
declare
cursor c is (select trunc((level+2)/3) lvkey, chr(ASCII('A')+mod(level*2,3)) letter, round(dbms_random.value(1,100)) val
from dual
connect by level <=10
);
type tabdata_t is table of c%rowtype index by binary_integer;
tabdata tabdata_t;
type letterlookup_t is table of binary_integer index by varchar2(10);
type keylookup_t is table of letterlookup_t index by binary_integer; -- number not allowed!
keylookup keylookup_t;
empty_key letterlookup_t;
begin
-- load data
open c;
fetch c
bulk collect into tabdata; -- notice no limit clause here. For larger record sets you need to use a loop and LIMIT!
close c;
-- index data
<>
for i in 1..tabdata.count loop
if keylookup.exists(tabdata(i).lvKey) then
if keylookup(tabdata(i).lvKey).exists(tabdata(i).letter) then
-- same key twice?
-- maybe add the values, maybe raise an error
raise dup_val_on_index;
else
dbms_output.put_line('build index KEY='||tabdata(i).lvKey||',+letter='||tabdata(i).letter);
keylookup(tabdata(i).lvKey)(tabdata(i).letter) := i;
end if;
else -- key not in index yet
dbms_output.put_line('build index +KEY='||tabdata(i).lvKey||',+letter='||tabdata(i).letter);
keylookup(tabdata(i).lvKey) := empty_key;
keylookup(tabdata(i).lvKey)(tabdata(i).letter) := i;
end if;
end loop build_index;
-- index is now complete.
-- Lets access the data using some combinations of keyLv and letters
-- Test the index first
dbms_output.put_line('Index 1B=>'|| to_char(keylookup(1)('B')));
dbms_output.put_line('Index 3A=>'|| to_char(keylookup(3)('A')));
--dbms_output.put_line('1F='|| keylookup(1)('F')); -- this will raise NO_DATA_FOUND
-- now fetch the data using the index
dbms_output.put_line('Data 1B=>'|| tabdata(keylookup(1)('B')).val);
dbms_output.put_line('Data 3A=>'|| tabdata(keylookup(3)('A')).val);
end;
/
Output
build index +KEY=1,+letter=C
build index KEY=1,+letter=B
build index KEY=1,+letter=A
build index +KEY=2,+letter=C
build index KEY=2,+letter=B
build index KEY=2,+letter=A
build index +KEY=3,+letter=C
build index KEY=3,+letter=B
build index KEY=3,+letter=A
build index +KEY=4,+letter=C
Index 1B=>2
Index 3A=>9
Data 1B=>62
Data 3A=>34
PL/SQL procedure successfully completed.
If we try to access a collection that does not exist we get an error (usually no_data_found). Since the index collections are always sparse, this is something to keep in mind. If you are not sure if the key combination is already indexed, then either check for existence or react on the NO_DATA_FOUND.
comparison
It is not easy to compare the two approaches. The first way looks slightly less complex. It depends also how familar other developers are with collections and especially with nested collections. For many the double parenthesis syntax “myCol()()” is a little complicated at the beginning.
For very complex scenarios the first way might be the better way. It depends on data distribution (the more sparsly populated the key combinations are, the better is this way) and on how many keys (=dimensions) we have.
I once measured the performance in a system where we needed 5 dimensions (5 different keys) to access some data. The combined key lookup was faster than building a complex collection of collection of collection of collection. But the additional time to concat the key values in the end also was a large performance burden.
So in my specific case lookup('A:B:C:D:E') >>> lookup('A')('B')('C')('D')('E')
I do not think this performance experience is representativ.
conclusion
It is possible to use two keys as an index collection to lookup data in the main collection. Nested collections is a tool that every plsql developer should know about. Only when we know our tools, we can decide when to use them or when not.