Sometimes I use a region of type PL/SQL Dynamic Content. It is rare and there are often better alternatives – like using a select over a pipelined table function – but it still happens.
If the plsql code errors out, then the error is not shown on the same page, but instead is presented as a page rendering error.
Here is a simplified example:
The PL/SQL Dynamic Content region looks like this
sys.htp.p('Hello APEX world!');
raise_application_error(-20201, 'Virus detected, world stopped!');
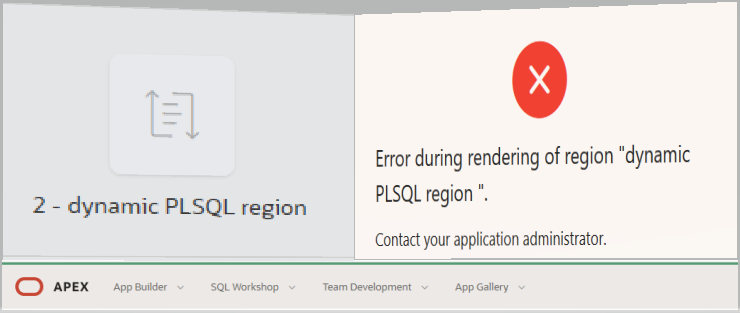
Running the page results in an ugly rendering error on a separate error page. See right display.
Remember the “Technical Info” part is not shown to the end user. So the error message is not shown.
Here is what I did to improve the error presentation. There might be better ways to do it, but it was a quick win and worked for me. So it might help you as well.
1. Capture the error message and write it to the page. Here I used a hidden div. The class “sqlerror” is used to mark the div.
begin
sys.htp.p('Hello APEX world!');
raise_application_error(-20201, 'Virus detected, world stopped!');
exception
when others then
-- currently this does not show the error at the page. This would work in a page process.
apex_error.add_error (
p_message => sqlerrm,
p_display_location => apex_error.c_inline_in_notification
);
--write error into hidden page item
sys.htp.p('<div class="sqlerror" style="display:none">'||sqlerrm||'</div>');
end;
2. After page load, use a dynamic action to find this error and display it.
We can not use the “After Refresh” event since PLSQL Dynamic Content regions are not refreshable. So it must be “Page Load”.
// test if there was an error during rendering of any region on the page
if ($('.sqlerror').length) {
//First clear the errors
apex.message.clearErrors();
// Now show new error
apex.message.showErrors([
{
type: "error",
location: [ "page" ],
message: $('.sqlerror').text(),
unsafe: false
}]);
}
Result:
A major difference is that everything that was already rendered at the time of error is now shown in the region. This might be wanted or could be unwanted.
Also we essentially hide the error from the apex engine. So when inspecting /utilities/Debug Messages/ we don’t see that error anymore.
Before the change we would get a debug entry like this
Since we suppressed all errors, we need to call apex_debug.error inside the plsql exception handler.
-- APEX debug instrumentation call
apex_debug.error ('Rendering of region failed! %s', sqlerrm);
And then we get such an entry in the APEX debug stack.
tested in APEX 19.2 and 20.1. It should also work in older versions, although the javascript api apex.message.showErrors might need to be replaced with some custom logic.
conclusion
The region type “PL/SQL Dynamic Content” is very different to normal APEX regions. Do not forget to implement and test some basic error handling if you must use such a region type.
Side node: In theory you should also watch out for an XSS attack. If somebody manages to add malicious code into the error message, it might be shown on the page. I didn’t test for that however.
The sample clause allows us to get a portion (a sample) of the tables data.
select *
from employees SAMPLE(20);
This returns 20 percent of the employees.
There is a ROW mode and a BLOCK mode. In BLOCK mode 20% of the blocks are returned, instead of 20% of the rows.
The sample clause has a second undocumented parameter.
select *
from employees SAMPLE(20, 0.5);
This also returns 20%. So far no obvious difference…
Jonathan Lewis mentioned that this second parameter is the number of consecutive groups/rows during row or block sampling. It was introduced during changes for the SAMPLE clause in 10g.
My non-representative tests showed that setting this parameter to 1 during block sampling makes sure we get results. Otherwise we frequently get blocks from the tables tablespace that are not filled with data. This seems to depend on the data distribution.
So… if a query like the following returns 0…
-- how many rows are in 1% of the blocks?
select count(*)
from employees SAMPLE BLOCK (1);
0
… then you can set the second parameter to 1 to be sure to get some data.
-- how many rows are in 1% of the blocks?
select count(*)
from employees SAMPLE BLOCK (1, 1);
Warning! This is only for testing purposes! It can potentially destroy your database.
alter system set "_exadata_feature_on"=true scope=spfile;
shutdown immediate;
startup;
Using this parameter we can test some of the newest options which are available only on exadata/cloud, like automated indexing.
5 – sequence cache is not lost during graceful database shutdown
Shutdown normal|immediate|transactional will not loose the sequence cache. Instead the next value will be used and set as last_number. Only a shutdown abort will loose the cache.
This was documented somewhere but I am not able to find it anymore. it might be that only older versions of the oracle docs still have this information.
To confirm it, I tested it. It works in SE and EE. It will probably not work in the same way on a RAC – because there is a separate cache for each instance.
There is an indirect mention of the behaviour in the 11g admin guide.
The database might skip sequence numbers if you choose to cache a set of sequence numbers. For example, when an instance abnormally shuts down (for example, when an instance failure occurs or a SHUTDOWN ABORT statement is issued), sequence numbers that have been cached but not used are lost. Also, sequence numbers that have been used but not saved are lost as well. The database might also skip cached sequence numbers after an export and import. See Oracle Database Utilities for details.
So a shutdown abort will loose the sequence cache. All other “organized” shutdowns will keep the cache intact.
The problem is that most DBAs seem way too keen on doing a shutdown abort. So loosing the sequence cache looks like the default behaviour, although it is not.
6 – reorder columns
We can change the logical column order by setting them invisible and making them visible again. This can be used to reorder columns in the column list. Important to understand is that the table is not physically changed, only the data dictionary entry is manipulated.
If we want to reorder columns physically, maybe to improve data compression, then this is not the way to do it.
example
create table t (col1 number, col2 number);
Table T created.
desc t;
Name Null? Type
---- ----- ------
COL1 NUMBER
COL2 NUMBER
/* make the first column invisible */
alter table t modify col1 invisible;
Table T altered.
desc t;
Name Null? Type
---- ----- ------
COL2 NUMBER
/* make the first column visible again */
alter table t modify col1 visible;
Table T altered.
desc t;
Name Null? Type
---- ----- ------
COL2 NUMBER
COL1 NUMBER
/* the column order is now reversed */
To physically reorder a table we need to export/import it, use dbms_redefinition or move the table.
Side note: The describe command in SQL*plus (and SQL Developer) will not show invisible columns. You can change that by setting the documented SQL*PLUS parameter COLINVISIBLE.
SET COLINVISIBLE ON
desc t;
Name Null? Type
---------------- ----- ------
COL2 NUMBER
COL1 (INVISIBLE) NUMBER
7 – object type “NON-EXISTENT”
Namespaces are used to avoid naming clashes between objects of different types. Among others the namespace 1 includes the object types table, view and function. So we can not have a table with the same name as a view or as a function.
There is a special object type in namespace 1 that is called “NON-EXISTENT”. This object type is used to mark dropped objects under edition based redefinition (EBR).
demo
Assuming 3 editions: ORA$BASE => CHILD1 => CHILD2
-- switch to base edition (ORA$BASE)
ALTER SESSION SET EDITION="ORA$BASE";
Adding editionable code in the parent edition ORA$BASE.
-- create a new function in base (EDITIONABLE is the default)
create function test_editions return varchar2
as
begin
return 'Base';
end;
/
Test the function in the child edition. It is usable. Although we didn’t create it there yet.
-- switch to child edition (CHILD1)
ALTER SESSION SET EDITION="CHILD1";
-- test function
select test_editions from dual;
TEST_EDITIONS
Base
function is functioning…
Now remove the function from the child edition, but not from the parent.
-- drop code
drop function test_editions;
-- test function again
select test_editions from dual;
ORA-00904: “TEST_EDITIONS”: invalid identifier
This error message was expected. The function was removed. No real object with the name “TEST_EDITIONS” exists (in namespace 1) in the edition CHILD1. Just to be on the safe side, double check in parent edition:
-- switch back to base and test function
ALTER SESSION SET EDITION="ORA$BASE";
select test_editions from dual;
TEST_EDITIONS
Base
function still functioning in BASE
This is also the result that was expected. The function still works in the parent edition.
What does the data dictionary say? A special view user_objects_ae shows the objects from all editions (_ae):
-- Check dictionary
select object_name, edition_name, object_type, namespace, editionable, status
from user_objects_ae
where object_name = 'TEST_EDITIONS';
OBJECT_NAME
EDITION_NAME
OBJECT_TYPE
NAMESPACE
EDITIONABLE
STATUS
TEST_EDITIONS
ORA$BASE
FUNCTION
1
Y
VALID
TEST_EDITIONS
CHILD1
NON-EXISTENT
1
VALID
TEST_EDITIONS
CHILD2
FUNCTION
1
Y
INVALID
We see that in edition “CHILD1” the object type of the function now is “NON-EXISTENT”. This is important, otherwise the database would not know to return the ORA-00904 error message when it searches for this object.
If the whole row would not exist, then the object in edition CHILD1 would be inherited from the parent edition ORA$BASE. This was the data situation before the function was actualized in CHILD1.
Even after we drop the function from all editions, then the dictionary will still show the NON-EXISTENT entries.
A side note/warning:
The status of the function in the second child edition CHILD2 is invalid after running the sample code. This dictionary entry was created, when the function was dropped in CHILD1.
This is because this function was never compiled in CHILD2. That means the code never was actualized there. And when we drop the code from all parent editions, then in CHILD2 any try to compile the code will not give an error, but the status will remain invalid.
This is why it is strongly recommended to recompile all editionable objects after some code changes, but especially after deletes/drops. Each recompile breaks the relationship to the parent and actualizes the code. So code changes in the parent will not propagate to the child anymore after it was recompiled at least once in the child.
8 – connect / as sysdba to PDB
Using a bequeath connection we can login to an Oracle database without a username and a password. This only works directly on the server using an os account that has enhanced privileges (part of the oradba group). To do so the ORACLE_SID environment variable needs to be set. However this connects only to the CDB.
It is possible to do the same using the undocumented environment variable ORACLE_PDB_SID to do the same against a PDB.
export ORACLE_SID=MYCDB
export ORACLE_PDB_SID=MYPDB
$ sqlplus / as sysdba
SQL> show con_name
CON_NAME
------------------------------
MYPDB
9 – print boolean values to serveroutput
There is an undocumented utility package sys.dbms_metadata_util that has a couple of interesting helper methods.
For example put_bool can be used to print boolean variables to serveroutput (using dbms_output).
-- print boolean values to dbms_output
set serveroutput on
begin
sys.dbms_metadata_util.put_bool('This is ', TRUE);
sys.dbms_metadata_util.put_bool('This is ', FALSE);
sys.dbms_metadata_util.put_bool('This is ', NULL);
end;
/
META:13:17:57.489: This is TRUE
META:13:17:57.489: This is FALSE
META:13:17:57.489: This is FALSE
PL/SQL procedure successfully completed.
There are also several other interesting functions in this package. For example a way to convert dictionary column values of type LONG into a CLOB variable.
There is a way to create the opposite of an SQL DML statement. For an insert we get a delete, for a delete we get an insert with the deleted column values and for an update we get an update with the previous values.
This is documented, but not many people know about. It is part of the flashback logic and more specifically the flashback transaction query.
Using Oracle Flashback Transaction Query
Use Oracle Flashback Transaction Query to retrieve metadata and historical data for a given transaction or for all transactions in a given time interval. Oracle Flashback Transaction Query queries the static data dictionary view FLASHBACK_TRANSACTION_QUERY, whose columns are described in Oracle Database Reference.
The column UNDO_SQL shows the SQL code that is the logical opposite of the DML operation performed by the transaction. You can usually use this code to reverse the logical steps taken during the transaction. However, there are cases where the UNDO_SQL code is not the exact opposite of the original transaction. For example, a UNDO_SQLINSERT operation might not insert a row back in a table at the same ROWID from which it was deleted.
Some security researchers (Alexander Kornbrust at DOAG 2019 – page 74) believe this poses an security risk, especially because it would allow us to find out about column values that are redacted. There are several ways to circumvent data redaction, and Oracle itself states that this feature is not ment as a high secure implementation (see Security Guidelines). So I don’t see that of a high risk. Using undo_sql to circumvent data redaction is the most complex hack I have seen so far – there are way easier methods.
Still an interesting feature. Here is an example. It needs a lot of non default settings to make it work.
example
Using the HR demo schema to test this.
First some steps to enable supplemental logging which is needed for undo_sql to work.
-- preparations as DBA in the CDB
select * from dba_pdbs;
alter session set container = CDB$ROOT;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
alter session set container = ORCL;
-- and as HR
ALTER TABLE HR.EMPLOYEES ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
Now we can do some changes.
-- as HR user
select * from hr.employees;
update hr.employees
set last_name = '--secret--'
where first_name = 'Randall';
2 rows updated.
delete from hr.employees
where first_name = 'Randall';
2 rows deleted.
Don’t commit or rollback yet. Simply change to another session/account.
-- as DBA
select undo_sql
from FLASHBACK_TRANSACTION_QUERY
where table_name='EMPLOYEES';
Result:
insert into "HR"."EMPLOYEES"("EMPLOYEE_ID","FIRST_NAME","LAST_NAME","EMAIL","PHONE_NUMBER","HIRE_DATE","JOB_ID","SALARY","COMMISSION_PCT","MANAGER_ID","DEPARTMENT_ID") values ('191','Randall','--secret--','RPERKINS','650.505.4876',TO_DATE('19-DEC-99', 'DD-MON-RR'),'SH_CLERK','2500',NULL,'122','50'); insert into "HR"."EMPLOYEES"("EMPLOYEE_ID","FIRST_NAME","LAST_NAME","EMAIL","PHONE_NUMBER","HIRE_DATE","JOB_ID","SALARY","COMMISSION_PCT","MANAGER_ID","DEPARTMENT_ID") values ('143','Randall','--secret--','RMATOS','650.121.2874',TO_DATE('15-MAR-98', 'DD-MON-RR'),'ST_CLERK','2600',NULL,'124','50'); update "HR"."EMPLOYEES" set "LAST_NAME" = 'Perkins' where ROWID = 'AAATiDAAMAAALKzABb'; update "HR"."EMPLOYEES" set "LAST_NAME" = 'Matos' where ROWID = 'AAATiDAAMAAALKzAAr';
-- as HR
rollback;
Alternatively run the 4 statements from undo_sql.
-- reset setup changes
-- as HR
ALTER TABLE HR.EMPLOYEES DROP SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
-- as DBA
ALTER DATABASE DROP SUPPLEMENTAL LOG DATA;
Conclusion
10 undocumented or unknown features. Some are useful, some are interesting, some are simple gaps in the documentation. I hope you found at least one that you didn’t know before and liked to read about.